




Axes de recherche
Vers une intelligence artificielle bio-inspirée
La grande majorité des approches modernes en vision par ordinateur repose fortement sur l'apprentissage automatique, et notamment sur l'apprentissage profond. Depuis bientôt une décennie, les réseaux de neurones artificiels convolutifs profonds sont devenus la méthode de référence pour de nombreuses tâches de vision : classification et détection d'objets ou d'actions, alignement de visages, etc. La disponibilité à la fois de très grandes quantités de données annotées et d'immenses ressources de calcul a permis les progrès remarquables de cette approche, mais ce succès arrive aux prix conséquents des coûts humains pour l'annotation manuelle des données et des coûts énergétiques non négligeables pour l'entrainement des CNN profonds.
En me démarquant des approches d'apprentissage profond couramment utilisées en vision, je m'intéresse à un type particulier de réseaux de neurones : les réseaux de neurones impulsionnels (Spiking Neural Networks, SNN), proches du modèle biologique, dans lesquels les neurones émettent des impulsions sortantes (potentiels d'action ou spikes) de manière asynchrone, en fonction des stimulations entrantes, asynchrones elles aussi. Ce type de réseaux de neurones présente l'avantage de réaliser un apprentissage majoritairement non supervisé (ce qui limite la nécessité de données manuellement annotées) grâce aux règles d'apprentissage bio-inspirées de type Spike-Timing Dependent Plasticity (STDP).
La règle STDP met à jour les poids synaptiques en fonction des relations de cause à effet constatées entre les impulsions entrantes et sortantes. Le but de cette règle, inspirée de la loi de Hebb, est le renforcement des connexions entrantes qui sont la cause des impulsions sortantes.
L'objectif à terme est d'utiliser ces modèles de réseaux de neurones pour résoudre des tâches modernes de vision par ordinateur en contournant un des principaux écueils des méthodes actuelles.

Apprentissage non supervisé de patterns temporels
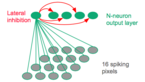
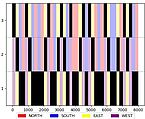
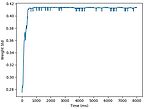
Je m'intéresse à la caractérisation du mouvement à l'aide de réseaux de neurones impulsionnels (SNN). Dans le cadre de la thèse de M. Veïs Oudjail (depuis Octobre 2018), nos premiers travaux ont visé la détection non supervisée de la direction du mouvement d'un motif.
Les premiers résultats obtenus avec les SNN ont démontré la capacité de ces réseaux à reconnaître et à caractériser les mouvements de motifs simples composés de quelques pixels (points, lignes, angles) dans une image. Nous considérons les séquences vidéos encodées au format Address-Event Representation (AER), comme celui produit par les capteurs de type Dynamic Vision Sensor. Ces capteurs se distinguent des capteurs vidéo classiques en cela qu'au lieu de produire des séquences d'images RGB ou niveau de gris, ils encodent de manière binaire une variation de luminosité positive ou négative, indépendamment pour chaque pixel. Ainsi, chaque variation d'un pixel à un instant donné se traduit par un événement correspondant transmis de manière asynchrone, avec une haute fréquence d'échantillonnage. Par ailleurs, cet encodage élimine une grande partie de la redondance dans l'information de mouvement - au prix de la perte des informations statiques de texture (constraste spatial). Ainsi, ces capteurs offrent une forme de représentation dynamique native du mouvement.
Le caractère asynchrone des SNN en fait un modèle susceptible de naturellement bien prêter au traitement de ce type de données : les événements générés par le capteur peuvent être traités et convertis pour nourrir la couche d'entrée du réseau.
La caractérisation du flux optique repose classiquement sur des traitements, opérateurs, et calculs complexes liés à la nature des capteurs physiques RGB conventionnels qui produisent des séquences d'images. Le portage bio-inspiré des traitements conventionnels en vision nécessite de repenser la manière de traiter l'information visuelle, en travaillant directement avec le contraste temporel et le mouvement. Cela laisse présager un traitement plus efficace.
Au delà de l'efficacité en termes de calculs, il est également attendu de disposer d'une information de meilleure qualité, dépourvue des bruits induits par les processus de captation et prétraitements usuels (dématriçage, compression, etc.) L'objectif est de proposer une chaîne de traitements bio-inspirés, du capteur au traitement de l'information visuelle.
Reconnaissance de gestes dans un contexte mobile
Dans la thèse de M. Cagan Arslan (depuis Oct. 2015) intitulée "Fusion de données pour l'interaction homme-machine", que je co-encadre avec mon collègue Prof Laurent Grisoni (encadrement inter-équipe avec l'équipe MINT dont la thématique est l'interaction tactile et gestuelle), nous visons l'exploitation des gestes d'un utilisateur dans des conditions diverses de captation (LEAP motion, Kinect, caméra fisheye sur un smartphone), et le couplage avec la modalité tactile (touchpad). Les gestes de l'utilisateur sont détectés et reconnus à l'aide de descripteurs visuels dédiés basés sur le flux optique.
Parce que les limites physiques des dispositifs posent des contraintes dans l'utilisation d'un système interactif (petit volume offert par le LEAP motion, petite surface du touchpad), nous envisageons à terme de nous placer un contexte multi-capteurs pour élargir la zone de captation (surface + volume). Cela demande de définir une transition (non triviale) entre les moyens de captation, et de gérer les incompatibilités techniques (e.g. fréquence d'échantillonnage, référentiels spatiaux et calibration), tout en tenant compte des limites physiques et cognitives de l'utilisateur dans la fusion.
Nos travaux ont donné lieu à 2 conférences d'audience internationale [Arslan18a] et [Arslan18b].
Reconnaissance bi-modale 2D-3D de visages
Concernant les données de profondeur, nous avons développé une approche bi-modale 2D-3D de reconnaissance de visages.
Un modèle complet a été défini, intégrant l'acquisition et la reconstruction 3D des données de profondeur à l'aide de caméras stéréoscopiques (illustration dans la figure) [Aissaoui13, Aissaoui12a-b, Aissaoui12.fr], un descripteur original Depth Local Binary Pattern représentant les données de profondeur des visages [Aissaoui14], et la fusion des modalités 2D-3D, a permis un important gain en robustesse dans la reconnaissance de visages [Aissaoui15a-b].
Enfin, un jeu de données disponible librement FoxFaces, contenant des données (images, séquences vidéo, profondeur stéréoscopique, profondeur mesurée par un capteur Time-Of-Flight) du visage de 64 sujets en variant la pose, l'expression faciale, et l'illumination a été créé et rendu public [Aissaoui16].

Annotation d'images en utilisant des ontologies
Dans le cadre de la thèse de Mme Jalila Filali (depuis Oct. 2015) intitulée "Approche de recherche d'images basée sur les ontologies et les mots visuels", que je co-encadre avec ma collègue Dr. Hajer Baazaoui de l'ENST de Tunis, nous souhaitons définir un modèle de représentation sémantique d'images utilisant des concepts en provenance d'un ontologie.
L'approche consiste à étoffer et raffiner une annotation "brute" issue d'une classification automatique (de type SVM ou CNN profond), en se basant une resource lexicale contenant des relations taxonomiques et sémantiques entre les concepts, ainsi que sur des règles d'inférence et de raisonnement. Nos travaux ont donné lieu à 2 conférences d'audience internationale [Filali17] et [Filali16].
Reconnaissance dynamique de personnes dans des vidéos
Concernant les données temporelles, un modèle de reconnaissance de personnes dans des flux vidéo, basé sur la ré-identification, a été proposé. Il consiste, dans un premier temps, à détecter, extraire et regrouper selon leurs identités toutes les occurrences de personnes (persontracks) : séquences visuelles dépourvues d'arrière-plan représentant des personnes) dans une vidéo de type journal télévisé ou débat, puis dans un second temps à étiqueter les persontracks et les clusters selon plusieurs stratégies de propagation d'identité.
Au cours de la première étape de regroupement, les persontracks sont mis en correspondance en se basant sur un descripteur original : les Histogrammes Spatio-Temporels [Auguste15b, Augusute12a-b.fr], qui présente l'avantage de prendre en compte les variations d'apparence dues aux mouvements des personnes dans le temps. Ce descripteur générique, qui met en correspondance des séquences vidéo, vise la ré-identification de personnes avec des applications possibles en vidéosurveillance (ex : suivi multi-caméra).
Ce modèle a été intégré avec succès dans le système de reconnaissance de personnes dans des contenus audiovisuels proposé par le consortium PERCOL (projet ANR du défi REPERE ANR/DGA), qui a été lauréat du challenge, devant deux autres consortiums [Bechet14].
Ici encore, un benchmark de ré-identification de personnes FoxPersonTraks (benchmark hébergé et distribué par ELRA, ISLRN: 168-132-570-218-1, ELRA ID: ELRA-S0374. Disponible librement pour les chercheurs académiques.} a été préparé par nos soins et rendu public. Il est composé d'un sous-ensemble des données diffusées dans le projet, détourées et manuellement filtrées. Il contient 4.604 persontracks (environ 170 minutes de vidéo) de 266 identités. Le jeu de données contient également des métriques et outils d'évaluation qui facilitent la comparaison des systèmes.

Vocabulaires visuels
Dans le contexte général de la représentation d'images, j'ai apporté un certain nombre de contributions visant à étendre le paradigme populaire des "sacs de mots visuels". Les trois contributions principales ont visé les objectifs suivants :
- l'enrichissement des descripteurs en intégrant aux caractéristiques des informations sur la distribution des points de contours dans le voisinage des points d'intérêt, au cours de la thèse d'Ismail El Sayad [ElSayad10d, ElSayad12],
- la simplification de la génération du vocabulaire visuel, en étudiant une alternative au clustering standard des descripteurs (KMeans), qui sélectionne les mots visuels en s'appuyant sur un critère de gain d'information apporté par les descripteurs, dans le cadre d'une collaboration avec Xlim [Le17, Urruty14],
- la proposition d'un modèle de représentation et d'appariement d'images adapté à la recherche d'images dans un contexte mobile comme illustré dans la figure, lors du projet européen ITEA TWIRL [Mennesson14].

Schémas de pondération pour les images
Je me suis attaché à définir des modèles de pondération, qui servent de pendants visuels des schémas de pondération utilisés pour le texte. Ces travaux ont été effectués à des niveaux croissants de granularité :
- un modèle de pondération spatiale pour les mots visuels (voir la figure : le descripteur "Edge Context" est d'abord généré dans l'espace 2D, après quantification des points d'un espace couleur-coordonnées 5D à l'aide d'une GMM, et ensuite le schéma de pondération estime pour chaque cluster gaussien g_i la contribution des features f_j pour le mot visuel w. La valeur tf pour le mot w est la moyenne de ces contributions) [ElSayad10d, ElSayad10a, ElSayad12] ;
- un modèle basé sur la perception des utilisateurs, mesurée à l'aide d'un gaze tracker, pour les régions d'images [Martinet13] ; et
- un modèle géométrique dédié aux objets de l'images [Martinet05, Martinet08, Martinet11] ainsi qu'aux graphes étoiles [Martinet02, Martinet03a-b]

Intégration des relations
J'ai étudié dans mes travaux la notion générale de relation, prise à trois différents niveaux.
Au bas niveau des mots visuels, nous avons défini des expressions visuelles (visual phrases) qui mettent en relation des mots visuels qui co-occurrent fréquemment (voir la figure) [Martinet07c, ElSaya10.fr, ElSayad10a, ElSayas11a-b, ElSayad12], en particulier au cours de la thèse d'Ismail El Sayad. La figure illustre un exemple d'expression visuelle découverte à l'aide de règles d'associations : les mots visuels correspondant à des yeux ainsi qu'à d'autres parties du visage (front, bouche, nez) sont associés dans l'expression visuelle "visage" . La combinaison de mots visuels et d'expressions visuelles dans la représentation des images a permis d'accroître la précision de classification sur la totalité des concepts du jeu de données Caltech-101.
À un niveau transverse, mes travaux ont visé l'annotation intermodale en mettant en relation des descripteurs issus de modalités visuelles et textuelles, notamment pendant mon postdoc [Martinet07a-b, Martinet07.misc].
Au haut niveau des objets sémantiques, j'ai proposé d'intégrer des relations (sémantiques, spatiales) entre les objets sous la forme de graphes étoiles (graphe conceptuel élémentaire composé d'une unique relation et de concepts qui lui sont attachés) dans la description des images [Martinet02.fr, Martinet03a-b].